回复消息代码实现
原创1. 定义回复消息枚举 ResponseMsgType
1. ///<summary> 2. ///公众号回复消息类型枚举 3. ///</summary> 4. public enum ResponseMsgType 5. { 6. text, 7. image, 8. voice, 9. video, 10. music, 11. ///<summary> 12. ///回复图文消息 13. ///</summary> 14. news, 15. }
2. 创建回复消息基类 ResponseBaseMassage
1. public class ResponseBaseMassage:BaseMassage 2. { 3. ///<summary> 4. ///回复消息类型 5. ///</summary> 6. public virtual ResponseMsgType MsgType 7. { 8. get {return ResponseMsgType.Text; } 9. } 10. }
3. 创建回复消息实体
(1)回复文本消息。
1. public class ResponseTextMessage: ResponseMessageBase 2. { 3. new public virtual ResponseMsgType MsgType 4. { 5. get {return ResponseMsgType.text;} 6. } 7. public string Content {get;set;} 8. }
(2)回复图片消息。
1. public class ResponseImageMessage: ResponseMessageBase 2. { 3. public ResponseImageMessage() 4. { 5. image = new image(); 6. } 7. new public virtual ResponseMsgType MsgType 8. { 9. get {return ResponseMsgType.image;} 10. } 11. public image image {get;set;} 12. } 13. public class image 14. { 15. public string MediaId {get;set;} 16. }
(3)回复语音消息。
1. public class ResponseVoiceMessage: ResponseMessageBase 2. { 3. public ResponseVoiceMessage() 4. { 5. voice = new voice(); 6. } 7. new public virtual ResponseMsgType MsgType 8. { 9. get {return ResponseMsgType.voice;} 10. } 11. public voice voice {get;set;} 12. } 13. public class voice 14. { 15. public string MediaId {get;set;} 16. }
(4)回复视频消息。
1. public class ResponseVideoMessage: ResponseMessageBase 2. { 3. public ResponseVideoMessage() 4. { 5. video = new video(); 6. } 7. new public virtual ResponseMsgType MsgType 8. { 9. get {return ResponseMsgType.video;} 10. } 11. public video video {get;set;} 12. } 13. public class video 14. { 15. public string MediaId {get;set;} 16. public string Title {get;set;} 17. public string Description {get;set;} 18. }
(5)回复音乐消息。
1. public class ResponseMusicMessage: ResponseMessageBase 2. { 3. public ResponseMusicMessage() 4. { 5. music = new music(); 6. } 7. new public virtual ResponseMsgType MsgType 8. { 9. get {return ResponseMsgType.music;} 10. } 11. public music music {get;set;} 12. } 13. public class music 14. { 15. public string Title {get;set;} 16. public string Description {get;set;} 17. public string MusicUrl {get;set;} 18. public string HQMusicUrl {get;set;} 19. public string ThumbMediaId {get;set;} 20. }
(6)回复图文消息。
1. public class ResponseNewsMessage: ResponseMessageBase 2. { 3. public ResponseNewsMessage() 4. { 5. Articles = new List<Articles>(); 6. } 7. new public virtual ResponseMsgType MsgType 8. { 9. get {return ResponseMsgType.news;} 10. } 11. public int ArticleCount 12. { 13. get{return (Articles ?? new Lise<Article>()).Count;} 14. set 15. { 16. 17. } 18. } 19. public List<Article>Articles {get;set;} 20. } 21. public class news 22. { 23. public string Title {get;set;} 24. public string Description {get;set;} 25. public string PicUrl {get;set;} 26. public string Url {get;set;} 27. }
基类中方法的参数有一个是 EnterParam 类型的,这个类是用户接入和验证消息真实性时需要使用的参数,包括 token、加密密钥、appid 等。定义如下:
1. /// <summary> 2. /// 微信接入参数 3. /// </summary> 4. public class EnterParam 5. { 6. /// <summary> 7. /// 是否加密 8. /// </summary> 9. public bool IsAes { get; set; } 10. /// <summary> 11. /// 接入 token 12. /// </summary> 13. public string token { get; set; } 14. /// <summary> 15. ///微信 appid 16. /// </summary> 17. public string appid { get; set; } 18. /// <summary> 19. /// 加密密钥 20. /// </summary> 21. public string EncodingAESKey { get; set; } 22. }
4. 关注消息与消息自动回复完整代码
1. using System; 2. using System.Collections.Generic; 3. using System.Web; 4. using System.Web.UI; 5. using System.Web.UI.WebControls; 6. using System.Data; 7. using System.IO; 8. using System.Net; 9. using System.Text; 10. using System.Xml; 11. using System.Web.Security; 12. using System.Text.RegulayEcpressionsl 13. namespace tencent.weixin 14. { 15. public partial class weixin : System.web.UI.Page 16. { 17. const string Token = 「yourToken」;//你的 Token 18. protected void page_load(object sender, EventArgs e) 19. { 20. if (Request.HttpMethod == 「POST」) 21. { 22. sring weixin = 「」; 23. weixin = PostInput();//获取 XML 数据 24. if(!string.IsNullOrEmpty(weixin)) 25. { 26. ResponseMsg(weixin);//调用消息适配器 27. } 28. } 29. } 30. #region 获取 POST 请求数据 31. private string PostInput() 32. { 33. Stream s = System.Web.HttpContext.Current.InputStream; 34. byte[] b = new byte[s.Length]; 35. s.Read(b, 0, (int)s.Length); 36. return Encoding.UTF8.GetString(b); 37. } 38. #endregion 39. #region 40. private void ResponseMsg(string weixin)//服务器响应微信请求 41. { 42. XmlDocument doc = new XmlDocument(); 43. Doc.LoadXml(weixin);//读取 XML 字符串 44. XmlElement root = doc.DocumentElement; 45. ExmlMsg xmlMsg = GetExmlMsg(root); 46. string messageType = xmlMsg.MsgType;//获取收到的消息类型 47. try 48. { 49. switch(messageType) 50. { 51. case 「text」: 52. textCase(xmlMsg); 53. break; 54. case 「event」: 55. if(!string.IsNullOrEmpty(xmlMsg.EventName)&&xmlMsg.EventName.Trim() ==「subscribe」) 56. { 57. int nowtime = ConvertDateTimeInt(DateTime.now); 58. string msg = 「感谢您的关注」; 59. string resxml = 「<xml><ToUserName><![CDATA [」+xmlMsg.FromUserName+「]]></ToUsetName><FromUserName><![CDATA[」+xml Msg.ToUserName+「]]></FromUserName><CreateTime>」+nowtime+「</CreateTime> <MsgType><![CDATA[text]]></MsgType><Content><![CDATA[」+msg+「]]> </Content><FuncFlag>0</FuncFlag></xml>」; 60. Response.Write(resxml;) 61. } 62. break; 63. case 「image」: 64. break; 65. case 「voice」: 66. break; 67. case 「video」: 68. break; 69. case 「location」: 70. break; 71. case 「link」: 72. break; 73. default: 74. break; 75. } 76. Response.End(); 77. } 78. catch(Exception) 79. { 80. } 81. } 82. #endregion 83. private string getText(ExmlMsg xmlMsg) 84. { 85. string con = xmlMsg.Content.Trim(); 86. System.Text.StringBuilder retsb = new StringBuilder(200); 87. retsb.Append(「这里放你的业务逻辑」); 88. retsb.Append(「接收到的消息:」+ xmlMsg.Content); 89. retsb.Append(「用户的 OPEANID:」+ xmlMsg.FromUserName); 90. 91. return retsb.ToString(); 92. } 93. 94. 95. #region 操作文本消息 + void textCase(XmlElement root) 96. private void textCase(ExmlMsg xmlMsg) 97. { 98. int nowtime = ConvertDateTimeInt(DateTime.Now); 99. string msg = 「」; 100. msg = getText(xmlMsg); 101. string resxml = 「<xml><ToUserName><![CDATA[」 + xmlMsg. FromUserName + 「]]></ToUserName><FromUserName><![CDATA[」 + xmlMsg. ToUserName + 「]]></FromUserName><CreateTime>」 + nowtime + 「</Create Time><MsgType><![CDATA[text]]></MsgType><Content><![CDATA[」 + msg + 「]]> </Content><FuncFlag>0</FuncFlag></xml>」; 102. Response.Write(resxml); 103. 104. } 105. #endregion 106. #region 将 datetime.now 转换为 int 类型的秒 107. /// <summary> 108. /// datetime 转换为 unixtime 109. /// </summary> 110. /// <param name=「time」></param> 111. /// <returns></returns> 112. private int ConvertDateTimeInt(System.DateTime time) 113. { 114. System.DateTime startTime = TimeZone.CurrentTimeZone. ToLocalTime(new System.DateTime(1970, 1, 1)); 115. return (int)(time - startTime).TotalSeconds; 116. } 117. private int converDateTimeInt(System.DateTime time) 118. { 119. System.DateTime startTime = TimeZone.CurrentTimeZone. ToLocalTime(new System.DateTime(1970, 1, 1)); 120. return (int)(time - startTime).TotalSeconds; 121. } 122. 123. /// <summary> 124. /// unix 时间转换为 datetime 125. /// </summary> 126. /// <param name=「timeStamp」></param> 127. /// <returns></returns> 128. private DateTime UnixTimeToTime(string timeStamp) 129. { 130. DateTime dtStart = TimeZone.CurrentTimeZone.ToLocal Time(new DateTime(1970, 1, 1)); 131. long lTime = long.Parse(timeStamp + 「0000000」); 132. TimeSpan toNow = new TimeSpan(lTime); 133. return dtStart.Add(toNow); 134. } 135. #endregion 136. private class ExmlMsg 137. { 138. /// <summary> 139. /// 本公众账号 140. /// </summary> 141. public string ToUserName { get; set; } 142. /// <summary> 143. /// 用户账号 144. /// </summary> 145. public string FromUserName { get; set; } 146. /// <summary> 147. /// 发送时间戳 148. /// </summary> 149. public string CreateTime { get; set; } 150. /// <summary> 151. /// 发送的文本内容 152. /// </summary> 153. public string Content { get; set; } 154. /// <summary> 155. /// 消息的类型 156. /// </summary> 157. public string MsgType { get; set; } 158. /// <summary> 159. /// 事件名称 160. /// </summary> 161. public string EventName { get; set; } 162. 163. } 164. 165. private ExmlMsg GetExmlMsg(XmlElement root) 166. { 167. ExmlMsg xmlMsg = new ExmlMsg() { 168. FromUserName = root.SelectSingleNode(「FromUser Name」).InnerText, 169. ToUserName = root.SelectSingleNode(「ToUserName」). InnerText, 170. CreateTime = root.SelectSingleNode(「CreateTime」). InnerText, 171. MsgType = root.SelectSingleNode(「MsgType」).Inner Text, 172. }; 173. if (xmlMsg.MsgType.Trim().ToLower() == 「text」) 174. { 175. xmlMsg.Content = root.SelectSingleNode(「Content」). InnerText; 176. } 177. else if (xmlMsg.MsgType.Trim().ToLower() == 「event」) 178. { 179. xmlMsg.EventName = root.SelectSingleNode(「Event」). InnerText; 180. } 181. return xmlMsg; 182. } 183. #endregion 184. } 185. }
聊天机器人是模拟人类对话或聊天的程序,世界上最早的聊天机器人诞生于 20 世纪 80 年代,名为「阿尔贝特」,用 Basic 语言编写而成。现在比较有名的聊天机器人有 Bily、Alise 等,由于中文对「词」划分模糊和语义繁多,因此国内聊天机器人发展相对较慢,有白丝魔理沙、赢思软件的小 i、爱博的小 A、小强、图灵机器人等。
微信公众号中的人工客服的一项重要的工作是与客户交流,这往往需要大量的人力成本,而且很难保证 24 h 不间断地提供服务。公众平台提供的关键词自动回复,虽然对用户的使用要求较高,但能够在一定程序上减少人工客服的压力,所以这部客服工作交由聊天机器人来完成。这样不仅节约人力成本,还能高效地处理琐碎的客服工作。
在微信公众号中接入聊天机器人有两种方式。一是在现有聊天机器人 API 接口的基础上搭建微信聊天机器人。目前中文聊天机器人有小黄鸡、图灵机器人等。其中,图灵机器人 API 接口免费,接入流程简单。二是自己开发聊天机器人。接入现有聊天机器人的方法简单,无须编程即可实现。以图灵机器人为例,只需申请图灵机器人账号,设置机器人信息以及接入微信公众平台的配置信息等就可完成。
开发聊天机器人需要了解聊天机器人的原理和开发过程。聊天机器人实现的原理与一般流程是,预先采集大量的问答知识,当收到用户的提问时,系统对问题进行词,判断该话题在系统知识库中存放的位置,为用户返回相应回答。所以聊天机器人的实现大概可以归纳为构建问答库、词、匹配。当然更高级的机器人也可以收集用户的问答知识,这就需要聊天机器人具有记忆功能,当用户提到知识库中没有的知识时能将该知识收集起来。这里开发的聊天机器人并没有记忆功能,主要功能是为用户返回知识库中能找到的相应的问答知识。实现原理如图 4-2 所示。
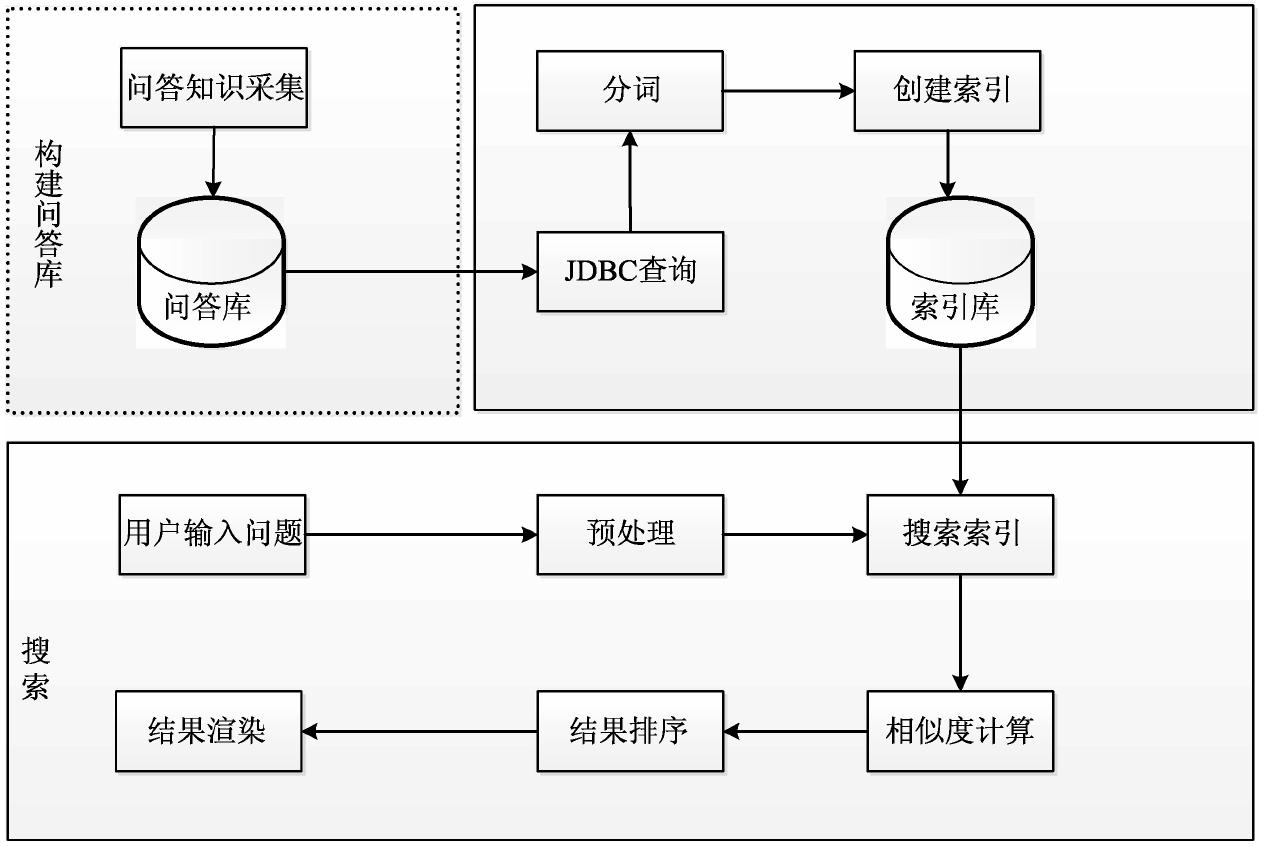
图 4-2 聊天机器人原理图
1. 问答知识库
机器人要想回答出客户所提的问题,那么首先就要具备自己的知识库,就和人类一样,逻辑分析的前提是需要储备与这个问题相关的知识。所以问答库中的记录越多,涉及的知识面越广,能够回答的问题就越多,回答的准确率也就越高。对于企业公众号而言,用户提的问题基本都可以通过企业客服知识库解决。
用户可能是咨询业务问题,也有可能是要求机器人讲笑话,还有可能仅仅是日常寒暄。
(1)对于业务问题,可以用企业客服知识库解决。
(2)对于日常寒暄,如果用户多次问同样的问题,要求回复不同的内容,问题与答案可能是一对一的,也可能是一对多的。
(3)如果用户最开始要机器人讲笑话,再发送「继续」「再来一个」「换个别的」等,机器人能理解用户的意思。
当机器人无法回答(无法匹配)时要有默认的回答。而在企业应用中,聊天机器人无法回答的问题应该交给人工客服处理。
按照以上的考虑,聊天机器人的问答知识库至少需要 4 张表:问答知识表、问答知识分表、笑话表和聊天记录表。问答知识表存储所有的问答对;问答知识分表存储某个问题对应多种回答的情况,将答案列表存储在知识分表中;笑话表主要存储一些幽默、搞笑、流行的段子;聊天记录表用于存储用户与聊天机器人的对话,这样才能进行上下文判断。
(1)问答知识表的建表语句如下。
1. create table 『knowledge』 ( 2. 『id』 int not null primary key comment 『主键标识』, 3. 『question』 varchar(2000) not null comment 『问题』, 4. 『answer』 text(8000) not null comment 『答案』, 5. 『category』 int not null comment 『知识的类别(1:普通话 2:英语 3:上下文)』 6. )comment=『知识问答表』;
answer 表示答案,一对一关系时,答案就存储在该字段中,而问题与答案是一对多关系时,该字段为空,答案列表存储在问答知识分表 knowledge_sub 中。
(2)问答知识分表的建表结构如下。
1. create table 『knowledge_sub』( 2. 『id』 int not null auto_increment primary key comment 『主键标识』, 3. 『pid』 int not null comment 『与 knowledge 表中的 id 相对应』, 4. 『answer』 text(8000) not null comment 『答案』 5. ) comment=『问答知识分表』;
(3)笑话表的建表结构如下。
1. create table 『joke』( 2. 『joke_id』 int(8) primary key not null auto_increment comment 『笑话 id』, 3. 『joke_content』 text(8000) not null comment 『笑话内容』, 4. ) comment= 『笑话表』;
(4)聊天记录表的建表结构如下。
1. create table 『chat_log』 ( 2. 『id』 int not null auto_increment primary key comment 『主键标识』, 3. 『open_id』 varchar(30) not null comment 『用户的 OpenID』, 4. 『create_time』 varchar(20) not null comment 『消息的创建时间』, 5. 『req_msg』 varchar(2000) not null comment 『用户上行的消息』, 6. 『resp_msg』 varchar(2000) not null comment 『公众账号回复的消息』, 7. 『chat_category』 int comment 『聊天话题的类别(0:未知 1:普通对话 2:笑话 3: 上下文)』 8. ) comment=『聊天记录表』;
2. 中文分词方法
知识库解决之后,最关键的问题就在于如何通过用户询问的问题找到知识库中最匹配的答案。首先要对用户的问题进行分词。如果用户提出的问题是「你对聊天机器人怎么看」,如果通过一个句子进行存储会太费时费空间,所以一般通过词进行存储。分词几乎成为聊天机器人的核心。英文一般通过空格分词,而中文博大精深、灵活多变,没有明显的分隔词,部分词语具有歧义性。所以中文分词方法比较复杂,发展也比国外缓慢。人类一般根据自己的认识与理解来区分词语,而聊天机器人根据分词算法进行区分。现有的分词算法有基于字符串匹配的分词算法、基于统计的分词算法、基于理解的分词算法。
(1)基于字符串匹配的词算法。
该算法又称为机械词或字典算法。这种方法是按照一定策略将待分析的汉字串与一个「充大的」机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。该方法有 3 个核心要素:扫描方向、匹配优先策略以及词典。根据扫描方向的不同分为正向匹配、逆向匹配和双向匹配。根据不同长度的匹配优先策略,分为最大(最长)优先和最小(最短)优先。常用的基于字符串匹配的词算法有正向最大匹配法、逆向最大匹配法与最小切分法。将正向最大匹配和逆向最大匹配方法结合起来的方法就是双向最大匹配法。
双向最大匹配法从正向和反向两个方向进行切分,并对两个切分结果进行比较,对不同的结果进行歧义识别。
基于字符串匹配的词算法的特点是速度快,复杂度为 O(n),相对较简单,效果正常。
(2)基于统计的词算法。
基于统计的词算法是按照相邻字出现的次数来判断构成一个词语的可能性。从形式上看,词是稳定的字的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此,字与字相邻共现的频率或概率能够较好地反映成词的可信度。
因此,统计分词的前提是需要一个原始语料库。可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。
(3)基于理解的词算法。
该算法是指计算机模拟人对句子的理解进行词。其基本思想是,在词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括 3 个部分:词子系统、句法语义子系统、总控部分。在总控部分的协调下,词子系统可以获得有关词、句子等的句法和语义信息来对词歧义进行判断,即它模拟了人对句子的理解过程。这种词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统性和复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的词系统还处在试验阶段。
到底哪种词算法的准确度更高,目前并无定论。对于任何一个成熟的词系统来说,不可能单独依靠某一种算法来实现,需要综合不同的算法。据了解,海量科技的词算法就采用「复方词法」。所谓复方,相当于中药中的复方概念,即用不同的药材综合起来去医治疾病。同样,对于中文词的识别,需要多种算法来处理不同的问题。
3. Lucene.Net 与中文分词算法
Lucene.Net 是基于 Java 的全文信息检索引擎工具包 Lucene 的.Net 移植版本。Lucene 并不是一个完整的全文检索引擎,而是一个架构,提供完整的全文索引引擎、查询引擎和部分文本分析引擎。但 Lucene 只能为文本类型的数据建立索引。
全文检索的基本思路是将非结构化数据中的一部分信息提取出来,重新组织,使其变得具有一定结构,然后对此数据进行搜索,从而使搜索相对较快。这部分从非结构化数据
中提取出重新组织的信息,称为索引。
(1)Lucene 的结构
Lucene.Net 的最新版本为 2012 年发行的 Lucene.Net 3.0.3 版本。从 Lucene 官网上下载最新源码,其源码包含 9 个包:Analysis、Document、Index、Messages、QueryParser、Search、Store、Support、Util。源码结构如图 4-3 所示。
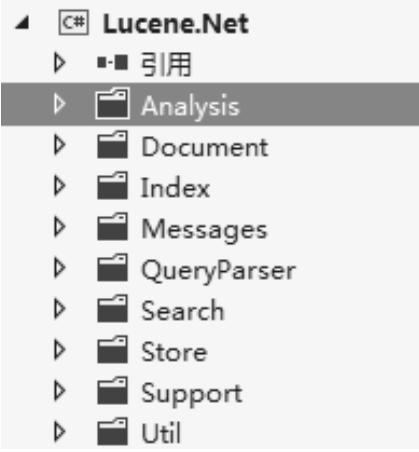
图 4-3 源码结构图
下面介绍 Lucene.Net 的部分包。
① Analysis 包
该包可对文档进行词,为索引工作做准备。它提供自带的 Analyzer 词器,包含英文空白字符词器 WhiteSpaceAnalyzer 和中文词器 SmartChineseAnalyzer 等。
② Document 包
该包中存放的是与 Document 相关的各种数据,包括 Document 类和 Field 类等。作用是管理索引存储的文档结构。Document 与 Field 的关系,类似于关系型数据库中表与字段的关系,或面向对象编程中对象与属性的关系。
③ Index 包
该包用于索引管理,包括索引的建立、删除、更新等,也包括索引的读写操作类等。最常用的是对索引进行读写操作的 IndexReader 类,还有对索引进行写、合并和优化的 IndexWriter 类。
④ QueryParser 包
QueryParser 属于查询分析器,主要负责查询语法分析。作用是实现查询关键词的各种运算,包括与、或、非等。
⑤ Search 包
该包的主要功能是根据条件从索引中检索结果。IndexSearcher 是搜索核心类,用于在指定的索引文件中进行搜索。
⑥ Store 包
该包负责数据存储管理,包括底层的 I/O 操作。Directory 定义了索引的存放位置,其中,FSDirectory 表示将索引文件存储在文件系统中,RAMDirectory 表示将文件存储在内存中,MMapDirectory 为使用内存映射的索引。
⑦ Util 包
该包包含 Lucene 所需要的一些工具类。通常将时间格式化、字符串处理等一些常用的工具类放在此包中,便于管理和重用。
Lucene.net 相关术语介绍如下。
• Analyzer,表示词器,主要作用是词,并去除字符串中的无效词语。
• Document,是索引和搜索的基本单元,类似于数据库中的一条记录。所有需要索引的数据都要转化成 Document 对象。
• Field,表示信息域,一个 Document 包含多个信息域,类似于数据库中的多个字段。Field 有两个属性:存储和检索。其中,存储属性能够控制是否存储 Field,检索属性能控制是否可以对 Field 检索。
• Term,条目。是搜索当中最小的单位,表示文档中的一个词语。
• Token,标记。Token 可以理解为 Term 的一次出现。Token 用来标记不同的词的位置信息,比如,一句话中可能出现多个相同的词,都用同一个 Term 表示,但拥有不同的 Token。
• Segment,不是所有的 Document 文件都是单独的一个文件,它首先被写入一个小文件,然后被写入大文件。其中,每个小文件都是一个 Segment。
Lucene 的索引原理图如图 4-4 所示。
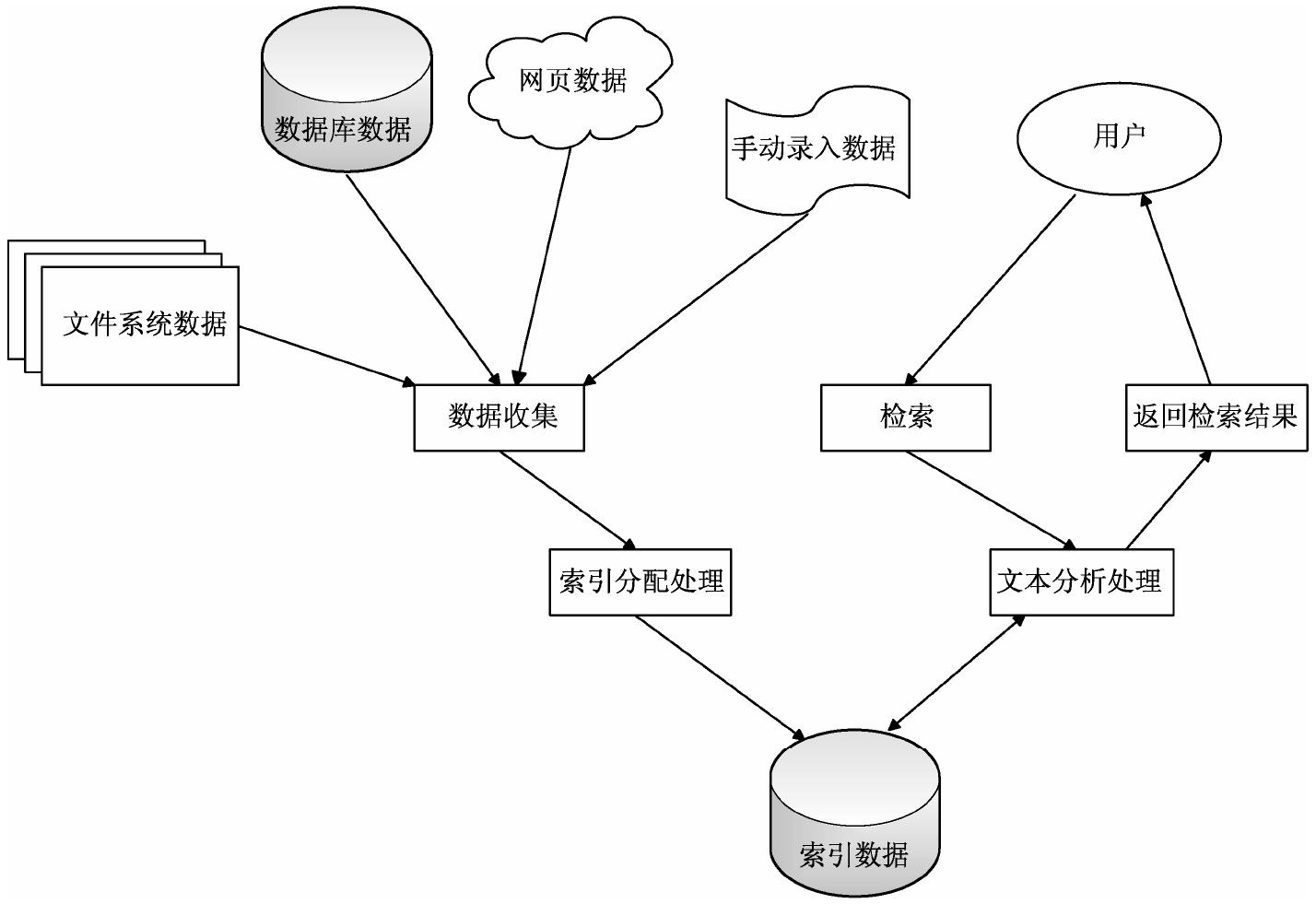
图 4-4 Lucene 的索引原理
(2)词器 IKAnalyzerNet
在 Lucene 中,我们已经知道 Analyzer 表示的是词器,包含单字词器 StandardAnalyzer、二分法分词器 CJKAnalyzer、ChineseAnalyzer、SmartChineseAnalyzer 等。我们的焦点是中文分词,以上分词器的缺点至少有两个:匹配不准确、索引文件大。
IKAnalyzer 是基于 Java 的开源的第三方词工具包,而 IKAnalyzerNet 是 IKAnalyzer 在.Net 的移植版本。该工具包采用正向迭代最细粒度切分算法,支持智能词和最细粒度词两种切分模式,使其词结果更准确、更智能化。使用 IKAnalyzerNet 词器结合 Lucene 进行词的示例如下:
1. using System; 2. using System.Collections.Generic; 3. using System.IO; 4. using Lucene.net.Analysis; 5. using IKAnalyzerNet; 6. namespace Weixin.Chatbot{ 7. public class AnalyzerTest{ 8. public static void Main(String[] args) throws Exception{ 9. String content =「使用微信公众平台接入聊天机器人」; 10. //使用 IKAnalyzerNet 算法对以上句子分词,true 为智能分词,false 为最细粒度分词 11. Analyzer analyzer = new IKAnalyzerNet(true); 12. //将字符串创建成分词流 13. TokenStream tokenStream = analyzer.TokenStream(「text」, content); 14. tokenStream.reset(); 15. //保存相应词汇 16. CharTermAttribute cta = null; 17. while(tokenStream.incrementToken()){ 18. cta= tokenStream.addAttribute(CharTermAttribute.class); 19. Console.writeline(cta.toString()+「」); 20. } 21. } 22. }
代码中使用了 IKAnalyzerNet 对 content 文本进行词,IkAnalyzerNet 中的构造方法需要传入一个 bool 类型的值,用于表示采用哪种词模式,其中 true 表示智能词,false 表示用最细粒度词。代码示例中采用的是智能词,其运行结果如下:
使用 微信 公众号 平台 接入 聊天 机器人
采用最细粒度分词的结果如下:
使用 微信 公众号 微信公众号 平台 接入 聊天 机器人 聊天机器人
版权保护: 本文由 李斯特 原创,转载请保留链接: https://www.wechatadd.com/artdet/9550